

Joe Teates ’28 has spent much of his summer inside an Olin Hall lab, supervising his robotic research partner, which is literally spinning its wheels on its quest for higher intelligence.
“Larry” — Teates says the name came to him one day and just stuck — is many hours into what we broadly think of as learning by doing.
Technically speaking, Larry is a robotic inverted pendulum. It is trying to solve a classic control problem by balancing upright a free-swinging arm attached to a rolling cart.
“It’s like balancing a broomstick in your hand,” computer science Professor Matt Kretchmar says. “That’s what it’s trying to do.”
This arrangement is inherently unstable, and the pendulum arm will fall over unless actively stabilized by the back-and-forth movements of the cart.
If you’ve ever attempted such a balancing act, you know that it is a complex and constantly changing affair, demanding a continuous stream of actions and reactions.
Making machines run through simulations is a fast and efficient way to teach them new tricks, but this research road taken by Teates is not so easily traveled.
Using an AI principle known as reinforcement learning, he’s teaching Larry to teach himself how to balance the pendulum. Teates provides computational guidance, but Kretchmar likens Larry’s learning process to teaching someone how to ride a bike.
“At a certain point you just have to get them out on the bike and push them down the sidewalk,” he says.
To do this, Teates taught Larry to rely upon a blend of exploration and exploitation. The robot is playing an extended game of trial and error, taking risks, learning from his mistakes, and applying what he learns along the way to reach his goal, all while Teates keeps an eye on his progress and makes tweaks as needed. Larry began with entirely random movements and fine-tunes its balancing act as it goes, based on what it has learned and the values Teates has set for it.


From a machine-learning standpoint, there is real value to this more complicated process. While simulations can accelerate learning, reinforcement learning algorithms encourage machines to adapt to the myriad uncertainties that arise, often unexpectedly, in settings outside a controlled lab.
“There are more applications for it in real life,” Teates says. “You learn to adapt what you already know to a new environment.”
“The real world,” Kretchmar says, “is messy.”
Teates has long been interested in computer science, and he came to Denison hoping for experiences exactly like the one the Summer Scholars program is affording him. He has the chance to conduct in-depth research in his chosen field with one-on-one guidance from a mentor, all before he has started his sophomore year.
“I would never be able to do this at a big school, especially my first year,” he says. “I learned a ton.”
That learning has been more wide-ranging than he expected. He hadn’t anticipated, for instance, that conducting sophisticated research in AI would require him to also learn to solder metal.
“There’s a lot of on-the-ground learning that comes with this,” Kretchmar says.
By the end of his Summer Scholars research, Teates had managed to get Larry to balance upright for five seconds. With success so close, Teates returned early to campus for the Fall 2025 semester to resume the work.
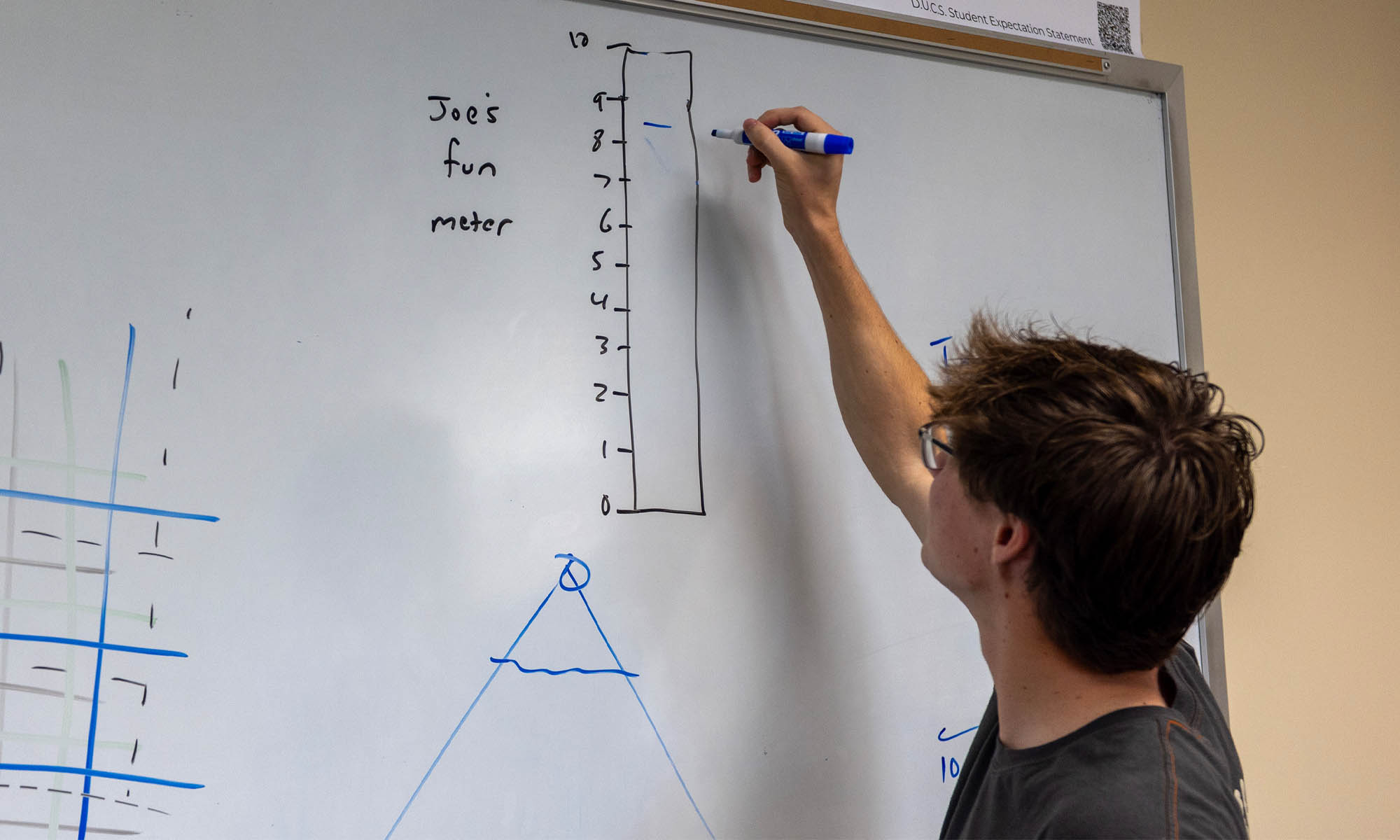
Encouraged by Kretchmar, Teates also made sure throughout his research to record essential data of another kind on a whiteboard. It was labeled, “Joe’s Fun Meter.”
Teates says even on the most difficult days of his research, he never sank below a 4 or 5.
“I love this work, as much as there are frustrations,” he says. “Seeing something work, seeing the end results, there’s really nothing like it.”





